Research News
Sep 13, 2022
New method to identify symmetries in data using Bayesian statistics
A Bayesian statistics-based method derives unprecedented exact integral formulas, allowing future applications in various areas, including genetic analysis.
Symmetries in nature make things beautiful; symmetries in data make data handling efficient. However, the complexity of identifying such patterns in data has always bedeviled researchers. Scientists from Osaka Metropolitan University and their colleagues have taken a major step towards detecting symmetries in multi-dimensional data by utilizing Bayesian statistics. Their findings were published in The Annals of Statistics.
Bayesian statistics has been in the spotlight in recent years due to improvements in computer performance and its potential applications in artificial intelligence. Bayesian statistics is a statistical approach that, even when data are insufficient, derives the probability of an event occurring by first setting a prior probability and then, whenever new information is obtained, calculating a posterior probability—an update to the prior probability—that the event will occur. The calculation of posterior probabilities requires complex calculations of integrals and therefore is often considered an approximation only.
Examples of colored graphs designating symmetries of four-dimensional data. Vertices and edges of the same color and shape in a graph are mapped to each other by a symmetry permutation preserving the structure of data.
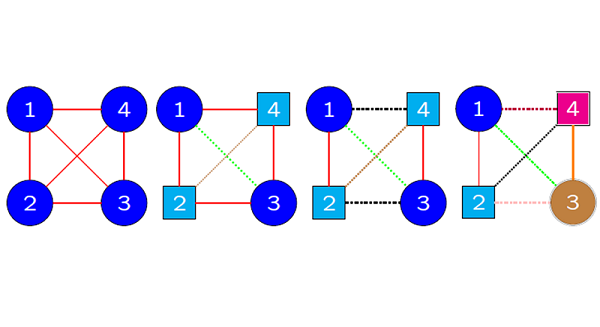
The international team including Professor Hideyuki Ishi from Osaka Metropolitan University, Professor Piotr Graczyk from the University of Angers, Professor Bartosz Kołodziejek from Warsaw University of Technology, and the late Professor Hélène Massam from York University (Toronto) has succeeded in deriving new exact integral formulas, and in developing a method to search for symmetries in multi-dimensional data using Bayesian statistical techniques.
When the amount of data to be handled increases, the optimal pattern must be selected from a vast number of patterns, making it difficult to solve the problem precisely. Addressing this challenge, the team has also developed an efficient algorithm for obtaining an approximate solution even in such cases.
In the words of Professor Ishi, “Symmetries in data are ubiquitous in a wide variety of models. Once symmetries are identified, the number of parameters required to display the structure of the data, and the number of samples required to determine the parameters, can be significantly reduced. In the future, the results of this research are expected to contribute to genetic analysis, discovering chromosomes that have the same function in different locations.”
Funding
The study was supported by JSPS KAKENHI Grant Number 16K05174, 20K03657, JST PRESTO, Grant 2016/21/B/ST1/00005 of the National Science Center, Poland, and an NSERC Discovery Grant.
Paper Information
Title: Model selection in the space of Gaussian models invariant by symmetry
Journal: The Annals of Statistics
DOI: 10.1214/22-AOS2174
Publication date: June 16, 2022
Contribution to SDGs

9: Industry, Innovation And Infrastructure
Contact
Graduate School of Science
Prof. Hideyuki Ishi
E-mail: hideyuki-ishi[at]omu.ac.jp
*Please change [at] to @.
SDGs
