Research News
Feb 1, 2023
Contributing to the Utilization of Big Data! Developing new data learning methods for artificial intelligence
Proposed a method for continual learning of data and their labels in multi-label classification problems
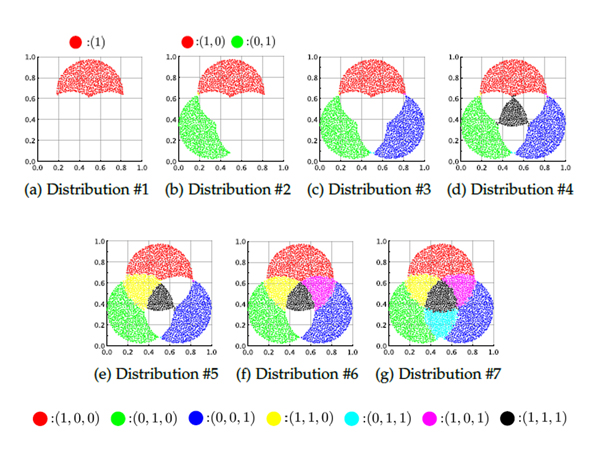
A process of continual learning for a synthetic multi-label dataset
The figure shows how new information is learned each time a data distribution is input, while retaining information learned in the past.
Advances in IoT technology have made it possible for us to easily and continually obtain large amounts of diverse data. Artificial intelligence technology is gaining attention as a tool to put this big data to use.
Conventional machine learning mainly deals with single-label classification problems, in which data and corresponding phenomena or objects (label information) are in a one-to-one relationship. However, in the real world, data and label information rarely have a one-to-one relationship. In recent years, therefore, attention has focused on the multi-label classification problem, which deals with data that has a one-to-many relationship between data and label information. For example, a single landscape photo may include multiple labels for elements such as sky, mountains, and clouds. In addition, to efficiently learn from big data that is obtained continually, the ability to learn over time without destroying things that were learned previously is also required.
A research group led by Associate Professor Naoki Masuyama and Professor Yusuke Nojima of the Osaka Metropolitan University Graduate School of Informatics, has developed a new method that combines classification performance for data with multiple labels, with the ability to continually learn with data. Numerical experiments on real-world multi-label datasets showed that the proposed method outperforms conventional methods.
The simplicity of this new algorithm makes it easy to devise an evolved version which can be integrated with other algorithms. Since the underlying clustering method groups data based on the similarity between data entries, it is expected to be a useful tool for continual big data preprocessing. In addition, the label information assigned to each cluster is learned continually, using a method based on Bayesian approach. By learning the data and learning the label information corresponding to the data separately and continually, so that both high classification performance and continual learning capability are achieved.
“We believe that our method is capable of continual learning from multi-label data and has capabilities required for artificial intelligence in a future big data society,” Professor Masuyama concluded.
The research results were published in IEEE Transactions on Pattern Analysis and Machine Intelligence on December 19, 2022.
Funding
This research was supported by Ministry of Education, Culture, Sports, Science and Technology, Leading Initiative for Excellent Young Researchers, and by Japan Society for the Promotion of Science Grant Number JP22K12199. As well as the Universiti Malaya Impact-oriented Interdisciplinary Research Grant Programme IIRG002C-19HWB, Universiti Malaya Covid-19 Related Special Research Grant CSRG008-2020ST from University of Malaya, the National Natural Science Foundation of China Grant No. 61876075, Guangdong Provincial Key Laboratory Grant No. 2020B121201001, the Program for Guangdong Introducing Innovative and Enterpreneurial Teams Grant No. 2017ZT07X386, The Stable Support Plan Program of Shenzhen Natural Science Fund Grant No. 20200925174447003, and the Shenzhen Science and Technology Program Grant No.KQTD2016112514355531.
Paper Information
Journal: IEEE Transactions on Pattern Analysis and Machine Intelligence
Title: Multi-label Classification via Adaptive Resonance Theory-based Clustering
DOI: 10.1109/TPAMI.2022.3230414
Author: Naoki Masuyama, Yusuke Nojima, Chu Kiong Loo, Senior, Hisao Ishibuchi
Publish: December 19, 2022
https://doi.org/10.1109/TPAMI.2022.3230414
Contact
Graduate School of Engineering
Naoki Masuyama
E-mail: masuyama[at]omu.ac.jp
*Please change [at] to @.
SDGs
